hanyangl5
Async Compute on Mali: Lessons from a Mobile Ray Tracing Experiment
Abstract
Async Compute is a well-known optimization technique on desktop GPUs, allowing compute and graphics workloads to run in parallel on independent hardware units. On ARM Mali GPUs, however, the parallelism is fundamentally different. This post documents a series of experiments optimizing real-time ray tracing on a mobile Mali GPU, revealing that Mali’s Async Compute only enables parallelism between the Tiler (fixed-function vertex/tiling hardware) and other tasks — not fine-grained parallelism across individual hardware units like the Execution Engine (EE). When the EE is fully utilized, overlapping compute and graphics work on separate queues yields zero performance benefit.
Background
Mobile GPUs based on ARM’s Mali architecture now support hardware ray tracing via Vulkan extensions (VK_KHR_acceleration_structure, VK_KHR_ray_query, VK_KHR_ray_tracing_pipeline). A natural question arises: can we use Async Compute to hide ray tracing costs, as is common practice on desktop GPUs?
To answer this, I conducted a series of experiments on a Mali GPU with HWRT support, progressively refining the approach based on profiling data.
Experiment 1: Ray Query Inside the Lighting Pass
The most straightforward approach is to embed rayQueryEXT calls directly into the existing Lighting Pass fragment shader:
layout(set = 0, binding = 0) uniform accelerationStructureEXT topLevelAS;
bool trace_shadow_ray(vec3 origin, vec3 direction) {
rayQueryEXT query;
rayQueryInitializeEXT(query, topLevelAS,
gl_RayFlagsTerminateOnFirstHitEXT, 0xFF,
origin, 0.01, direction, 1.0);
rayQueryProceedEXT(query);
return rayQueryGetIntersectionTypeEXT(query, true)
!= gl_RayQueryCommittedIntersectionNoneEXT;
}
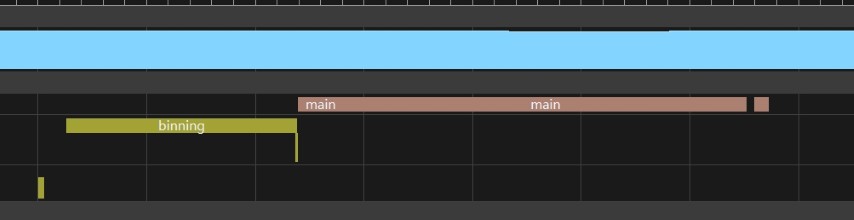
Result: The Lighting Pass execution time increased significantly. This is expected — ray traversal and intersection testing add substantial ALU and memory pressure to an already heavy fragment shader. The entire frame becomes bottlenecked on this single pass.
Conclusion: Inlining ray queries into a heavy fragment pass is not viable. The cost is additive and directly increases frame time.
Experiment 2: Separate RT Compute Pass with Async Compute
To decouple ray tracing from the main rendering pipeline, I restructured the frame as follows:
- Extract all ray tracing logic into a standalone Compute Shader using
rayQueryEXT - Schedule this RT Compute Pass on the compute queue
- Overlap it with a heavy fragment workload on the graphics queue, placed between the geometry pass and the lighting pass
The pipeline structure:
Geometry Pass
├─ [Compute Queue] RT Compute Pass (ray query)
└─ [Graphics Queue] Heavy Fragment Pass
Lighting Pass (consumes RT results)
The intent was to leverage Mali’s Async Compute capability: while the graphics queue processes fragment work, the compute queue simultaneously executes the RT pass, effectively hiding the ray tracing cost.
Observation via AGI (Android GPU Inspector)

Inspecting the GPU queue timeline in AGI confirmed that the compute and graphics queues do overlap in time. The RT Compute Pass and the Heavy Fragment Pass appeared to execute concurrently.
However, there was no FPS improvement whatsoever. Frame time remained identical to the non-async baseline.
This was the critical observation: queue-level concurrency does not imply hardware-level parallelism.
Experiment 3: GPU Counter Analysis
To understand why queue overlap produced no performance gain, I examined hardware performance counters (GPU Counters) in detail.
Key Finding
Regardless of which pipeline type was used — graphics, compute, or ray tracing — whenever shader work was active, the Execution Engine (EE) utilization remained at ~100%.
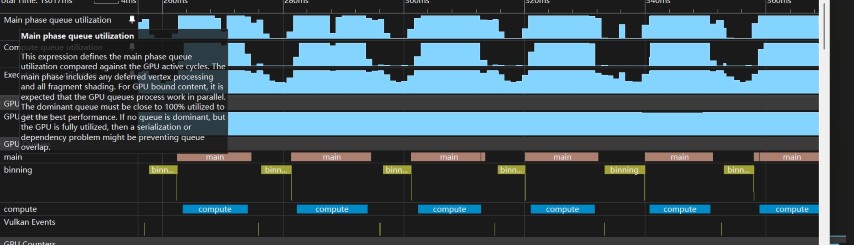
This held true across all tested configurations:
| Pipeline Type | Workload | EE Utilization |
|---|---|---|
| Graphics (Fragment Shader) | Lighting computation | ~100% |
| Compute (Compute Shader + Ray Query) | Ray tracing | ~100% |
| Ray Tracing Pipeline | Ray tracing | ~100% |
The EE is the shared programmable shader core on Mali. All shader execution — whether dispatched from the fragment queue or the compute queue — ultimately runs on the same pool of Execution Engines. When EE utilization is already saturated by fragment work, additional compute work cannot execute in parallel. It must wait for EE cycles to become available.
Architectural Analysis: What Async Compute Actually Means on Mali
Mali GPUs use a tile-based deferred rendering (TBDR) architecture with the following key hardware components:
┌──────────────────────────────────────────┐
│ Mali GPU │
│ │
│ ┌──────────┐ ┌─────────────────────┐ │
│ │ Tiler │ │ Execution Engine │ │
│ │ (Fixed │ │ (Programmable │ │
│ │ Function)│ │ Shader Cores) │ │
│ └────┬─────┘ └──┬──────────────┬───┘ │
│ │ │ │ │
│ │ ┌───┴───┐ ┌────┴──┐ │
│ │ │Compute│ │Fragment│ │
│ │ │ Queue │ │ Queue │ │
│ │ └───────┘ └───────┘ │
│ │ │
│ Vertex/Tiling Shader │
│ (runs on Tiler HW) Execution │
│ (runs on EE) │
└──────────────────────────────────────────┘
The parallelism model is:
-
Tiler ↔ EE: The Tiler is a dedicated fixed-function unit that handles vertex shading and tile binning. It operates independently from the Execution Engines. When the Tiler is active, the EE may be idle or underutilized — this is the window where Async Compute can provide real benefits.
-
Compute ↔ Fragment on EE: Both compute and fragment workloads are dispatched to the same Execution Engines. When EE utilization is high (which it typically is during fragment-heavy passes), there is no spare capacity for additional compute work. The queues may overlap at the scheduling level, but the hardware execution is effectively serialized.
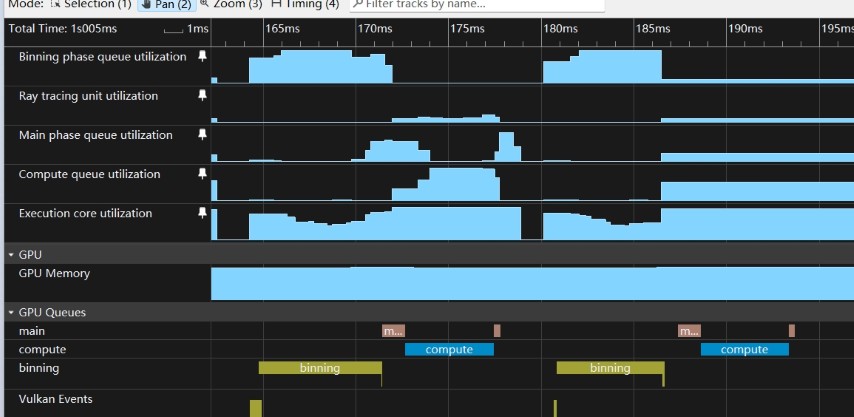
This is fundamentally different from desktop GPUs (e.g., NVIDIA Ampere/Ada), where independent hardware partitions (such as separate SMs or GPC-level scheduling) can process compute and graphics work truly in parallel.
Correct Optimization Strategy
Given the above findings, the viable strategy for Async Compute on Mali is:
Insert compute or RT work during Tiler-dominated phases, when the Execution Engines are underutilized.
Practical Guidelines
-
Profile EE utilization across the frame using GPU Counters. Identify phases where EE utilization drops — these typically correspond to geometry-heavy passes where the Tiler is the bottleneck.
-
Schedule RT work to overlap with Tiler phases. If a geometry pass is Tiler-bound, dispatching a lightweight RT compute pass on the compute queue during this window can yield genuine parallel execution.
-
Bound the RT workload. The RT pass should complete within the duration of the Tiler phase. Any excess spills into the fragment phase and competes for EE cycles, negating the benefit.
-
Verify with counters, not queue timelines. AGI queue timelines can be misleading — they show scheduling overlap, not hardware utilization. Always validate with EE utilization counters.
Observations from Production Mobile Titles
In practice, most mobile games using deferred rendering pipelines make minimal use of the compute queue. This means the Tiler phases often represent an untapped window where lightweight async work (including ray tracing) can execute with near-zero frame time impact — provided the workload is appropriately sized.
Summary
| Experiment | Approach | Outcome |
|---|---|---|
| #1 | Ray Query inlined in Lighting Pass | Frame time increased proportionally |
| #2 | Separate RT Compute Pass + Async Compute | Queue overlap observed, but zero FPS gain |
| #3 | GPU Counter analysis | EE utilization at ~100% — confirmed shared bottleneck |
Key takeaway: On Mali, do not rely on queue-level overlap as evidence of parallel execution. The only true parallelism available via Async Compute is Tiler vs. EE workloads. For mobile ray tracing, this means scheduling RT work to coincide with Tiler-bound phases, where the Execution Engines have spare capacity.